

Sentiment Analytics is a mar-tech product belonging to the communications platform, which can extract sentiments and provide cues on customer intent from conversational data. Unlocking the power of language, sentiment analysis stands at the forefront of natural language processing (NLP), offering insights into the emotional tone of textual content. This blog provides a concise yet thorough technical overview of sentiment analysis.

“Emotions are essential parts of human intelligence. Without emotional intelligence, Artificial Intelligence will remain incomplete.” Amit Ray
Evolution of Sentiment Analysis
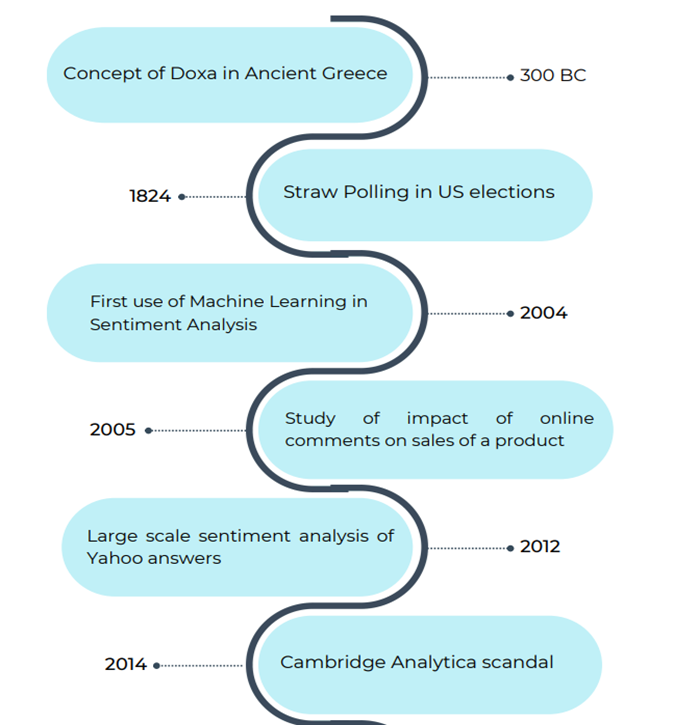
This section explores the evolution of Sentiment Analysis, starting with Ancient Greece’s concept of Doxa and progressing through key milestones. From the 1824 Harrisburg Pennsylvanian straw polling to the 2014 Cambridge Analytica scandal, it highlights studies on the influence of online comments on product sales. The timeline reflects the journey – from early attempts to predict outcomes – to the integration of advanced techniques in understanding and analyzing human sentiments.
Technical Overview
This section delves into sentiment analysis technicalities, from data handling to deployment. We examine both traditional models like Naive Bayes and Support Vector Machines and advanced deep learning models like RNNs and Transformer Models. The training phase involves supervised learning, and the deployment section explores integration, customization, and maintenance, with a note on cloud deployment for practical applications.
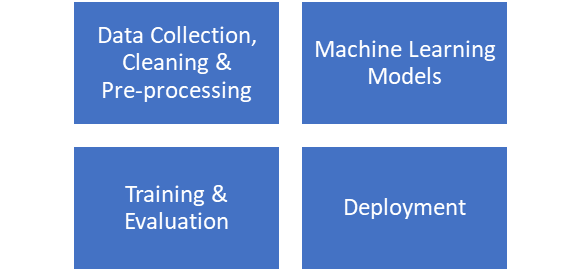
a) Data Collection, Cleaning & Preprocessing
Data collection and preprocessing plays a vital role in the success of sentiment analysis. Ensuring that the data is clean, relevant, and properly structured is essential to building accurate sentiment analysis models.
Data Collection
- Data sources : Identifying and collecting relevant textual data from various sources, such as social media, customer reviews, news articles, and surveys.
- Web scraping : Web scraping is the process of automatically extracting data from websites, turning web content into usable information for various purposes.
- White-listing : This is a cybersecurity practice that allows only approved, trusted entities or items to access a system or network while blocking all others.
- Data licensing : Ensuring that the data collected is obtained legally and adheres to copyright and data privacy regulations.
- APIs : Application Programming Interface is like a bridge that allows different software programs to talk to each other, enabling them to share and use each other’s functionalities and data.
Data Cleaning
- Text normalization : Standardizing the text by converting it to lowercase, removing extra white spaces, and handling special characters.
- Removing noise : Eliminating irrelevant information, such as advertisements, boilerplate text, and non-textual elements like images or video.
- Handling missing data : Addressing missing or incomplete data points, which can involve imputing missing values or omitting incomplete records.
- Duplicity check : Identifying and removing duplicate entries in the dataset to avoid biasing the analysis.
Text Pre-processing
Unlike structured data, features are not explicitly available in text data. So we need to use a process to extract features from text data. Here are pre-processing functions that can be performed on text data.
- Bag-of-Words (BoW) model : This is like making a list of all the words in your text, ignoring their order, to understand what words are present.
- Creating count vectors for dataset : It’s like counting how many times each word appears in your text, so you can see which words are used more often.
- Displaying document vectors: This helps turn your text into numbers, like a secret code, to help computers understand it better.
- Removing low-frequency words & stop words: We throw away words that hardly appear and words like ‘the’ or ‘and’ because they don’t tell us much about the text’s meaning.
- Distribution of words across different sentiments: We check which words are used more in positive, negative, or neutral texts to learn what words are linked to different feelings.
b) Traditional & Deep Learning Models
In the realm of sentiment analysis, machine learning models act as the core engines that enable computers to comprehend and categorize emotions & opinions within text data.

Traditional Models
- Naive Bayes : It is like a smart guesser. It looks at the words in a text and guesses if it’s positive, negative, or neutral by counting how often certain words are associated with those feelings. It’s simple and suited for sentiment analysis tasks with limited computational resources.
- Support Vector Machines (SVM) : A powerful and versatile model for text classification, it is known for its effectiveness in sentiment analysis and other NLP tasks. It is like a smart line that tries to find the best way to separate things. In sentiment analysis, it figures out whether a piece of text is happy, sad, or neutral by drawing a line between them.
Deep Learning Models
- Recurrent Neural Networks (RNN) : Useful for capturing sequential information in text data and making them valuable for sentiment analysis in longer text segments. A Recurrent Neural Network is like a text detective that looks at one word at a time and remembers what it saw before to understand how words relate to each other in a sentence. This helps RNNs figure out the feelings in a piece of writing, like whether it’s positive or negative.
- Transformer Models (BERT, GPT etc.) : Advanced deep learning models that have set new benchmarks in natural language processing, offering state-of-the-art performance in sentiment analysis. Transformer models are like super-smart robots that read and understand text really well. They can figure out the meaning of words and sentences by looking at how they are connected to each other, helping computers understand human language better.
c) Training and Evaluation
In the world of sentiment analysis, training and evaluation are like the practice sessions and performance reviews for your sentiment-detecting models.

- Teaching the computer : We start by giving the computer lots of examples of text with emotions, like happy or sad. This helps it learn how to recognize these emotions in text.
- Testing how well It learned : After training, we test the computer with new text it hasn’t seen before. We use rules to see if it can guess the right emotion. For example, can it tell if a review is positive or negative?
- Checking for mistakes : We also look at how often the computer makes mistakes. If it gets too many wrong, we need to make it better.
- Using it in the real world: Once the computer does well in testing, we can use it to understand emotions in things like customer feedback or social media. This helps businesses and researchers a lot.
- Supervised learning : In the training phase of sentiment analysis, one of the key approaches is supervised learning. This method involves teaching a machine learning model to recognize and categorize sentiments by providing it with a labeled dataset. It forms the foundation for many sentiment analysis applications.
- Challenges : We should know that there can be problems, like the computer learning too much from one example or not enough. So, we need to be careful when teaching the computer.
d) Deployment
The deployment phase represents the critical transition from the experimental development of sentiment analysis models to their practical implementation. It is the stage where the models are made ready for use in real-world scenarios and integrated into various applications, systems, or processes.
- Integration : Integrating sentiment analysis models into existing software systems, websites, or applications requires technical expertise. APIs and software libraries are often used to make this integration smooth and efficient.
- Customization : Sentiment analysis models can be customized for specific industries or niches. This might involve adapting the model’s training data or fine-tuning its parameters to align with industry-specific language and context.
- Ongoing maintenance: Continuous updates and maintenance are critical to keeping sentiment analysis models relevant. Language evolves, and context changes, so models must adapt to stay effective.
A Special Note on Cloud Deployment

Sentiment analysis is adaptable and can work with platforms like AWS and Azure. You can pick the cloud system that fits your needs and current setup, making it a versatile choice for different situations. It can be deployed on these platforms to take advantage of the numerous features of cloud computing. For example in speech recognition and translation capabilities, a solution can be designed to seamlessly integrate with cloud-based services like Azure Cognitive Services or AWS Transcribe and Translate.
Additionally, for scenarios where an internet connection may not be readily available, the solution can be operated in a completely offline mode. Businesses can opt for on-premises deployment within their local network. This may lack the scalability and external data access provided by cloud solutions.
About the Author

Joel Justin is a final year computer science engineering student at CMR Institute of Technology. His areas of interest includes programming, database management systems, software testing and digital possibilities. He is currently involved in a project for creating a lyrical language model for Indian languages.